|
奇怪的需求(2)兼容旧设备的Blog
今年年初我并没有像往年一样,总结去年一年中收集到的各种古董设备。一方面是因为24年确实也没收集到什么新东西,另一方面也是因为孩子尚小没太多时间去仔细折腾。当然,这并不意味着在“垃圾处理”领域任何动作都没有。经过几年的折腾,我手头的大多数老设备都可以通过各种方式连接至互联网,可以好好回味一把儿时网上“冲浪”的乐趣。
然而很快我就发现了问题,在如今 HTTPS 已经普遍性的应用于各大站点的前提下,不支持哪怕是 TLS 1.0 的旧设备的联网能力事实上等同于不存在。加之旧版本浏览器并不支持诸如 JS 和 HTML5 等现代前端技术,又将即便未使用 HTTPS 得现代站点排除在外。这样下来,能够被老设备正常访问的站点实际上屈指可数,那我花费时间精力实现的旧设备联网能力就显得毫无意义了。
当然,RetroComputing圈子对这种问题早已有了自己的解决方案。HTTPS的问题最容易解决,很久前就有爱好者使用低功耗计算机如树莓派等进行“HTTPS脱壳”,将 HTTPS 流量转换为普通 HTTP。当然,这样的脱壳方案适应的设备数依然有限,现代JS和HTML5仍然是挡在古董设备面前的鸿沟。因此,也有爱好者利用Web Archive(互联网档案馆)或类似服务,把网站的历史版本保存下来,形成所谓的“时光机”页面。甚至搭配硬件实现“互联网时光机”。(见:【熟肉】我组装了一台互联网时光机【The Science Elf】_哔哩哔哩_bilibili)。
当然,除了这些相对复杂的方式外,最简单的兼容旧设备的方法莫过于直接以1990s的技术构建一个古董站点,极致的静态页面,极致的享受(误。知乎“古董电脑室”专栏的主持人Dr.Quest曾经专门写过《Y2K网页制作全攻略》系列文章,来帮助大家实现“原生”古董页面的创建需求。当然,这种方式也存在着固有缺陷,一是几乎不可能实现现代前端技术一样的美观度,二是意味着现有博客的内容完全无法被利用,每个页面都需要新建、排版。
本站使用WordPress构建,基于PHP。因此理论上就存在一种可能,通过一个兼容旧浏览器的静态页面模板+WordPress内容导出脚本,构建一个降级版的站点。并且只需在为这个降级站点赋予一个独立的二级域名,关闭HTTPS,即可实现对旧设备的兼容。
而兼容目标很容易就确定为了IE3,原因很简单,从IE3开始IE的市占率超过了Netscape。在之后的10余年里,IE的HTML实现事实上就是互联网的标准。因此,如果页面元素兼容IE3,那么基本可以覆盖所有旧设备。
与现代HTML页面相比,IE3不支持以下特性: CSS2/3 JavaScript 的 DOM 操作 HTTPS(除非使用 SSLv2/3) PNG 格式图片 UTF-8 编码(默认是 ANSI/Latin-1) HTTP/1.1(只有部分支持)
因此,页面模板也不存在上述内容,仅通过<table>构建页面静态页面主体。主要代码如下 <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> …… <body bgcolor="#EFF3FF" text="#000000" link="#0000FF" vlink="#800080"> <center> <table width="600"> …… <tr><td> <font face="宋体" size="3"><b>最新文章</b></font><br><br> <!-- Begin Articles --> <font face="宋体" size="2"> <!-- 此处将被替换为生成的文章内容 --> </font> <!-- End Articles --> </td></tr></table> <br> <table width="600"> <tr><td align="center"> <font face="宋体" size="2"> <!-- Begin Pagination --> <a href="index2.html">下一页</a> <!-- End Pagination --> </font> </td></tr></table> <br><table width="600"> <tr><td> …… </table> </center> </body> </html>
与之配套的,我们需要一个适配WordPress的导出脚本,从现代页面中导出文档的相关内容,同时处理图片等标签元素。导出内容部分直接依赖wp-load.php,该文件直接提供了加载文章内容所需的相关函数。
图片处理相关代码如下: function extract_and_convert_images($content, $post_id, &$image_counter) { preg_match_all('/<img[^>]+src=[\"\']([^\\"\']+)[\"\']/i', $content, $matches); $converted_images = []; foreach ($matches[1] as $img_src) { $img_ext = pathinfo(parse_url($img_src, PHP_URL_PATH), PATHINFO_EXTENSION); $gif_name = "post{$post_id}_img{$image_counter}.gif"; $output_path = "legacy/images/$gif_name"; $image_data = @file_get_contents($img_src); if ($image_data !== false) { file_put_contents("temp.$img_ext", $image_data); exec("convert temp.$img_ext -resize 500 -colors 64 $output_path"); unlink("temp.$img_ext"); $converted_images[$img_src] = $gif_name; $image_counter++; } } return $converted_images; }
获取和处理相关文档内容主要代码如下: <?php require('wp-load.php'); …… for ($page = 0; $page < $total_pages; $page++) { …… foreach ($slice as $post) { …… // remove all <iframe> <video> <audio> <script> <style> tags $content = preg_replace([ '/<iframe[^>]*>.*?<\/iframe>/is', '/<video[^>]*>.*?<\/video>/is', '/<audio[^>]*>.*?<\/audio>/is', '/<script[^>]*>.*?<\/script>/is', '/<style[^>]*>.*?<\/style>/is' ], '', $content); // process <figcaption> tags $content = preg_replace_callback( '/<figcaption[^>]*>(.*?)<\/figcaption>/is', function ($matches) { $text = strip_tags($matches[1]); return "\n<font face=\"黑体\" color=\"#808080\" size=\"2\"><i>$text</i></font>\n"; }, $content ); // remove <span> tags $content = preg_replace('/<span[^>]*>.*?<\/span>/is', '', $content); $image_counter = 0; $converted_images = extract_and_convert_images($content, $post->ID, $image_counter); $patterns = []; $replacements = []; // replace all <img> tags src foreach ($converted_images as $original => $converted) { $escaped = preg_quote($original, '/'); $patterns[] = '/<img([^>]+?)src\s*=\s*(["\'])' . $escaped . '\2/i'; $replacements[] = '<img$1src="images/' . $converted . '"'; } …… $content = iconv("UTF-8", "GB2312//IGNORE", $content); $post_html = "<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 3.2 Final//EN\"> <html> <head><meta http-equiv=\"Content-Type\" content=\"text/html; charset=GB2312\"> <title>$title</title></head> <body bgcolor=\"#FFFFFF\" text=\"#000000\"> …… </body></html>"; file_put_contents("legacy/post_" . $post->ID . ".html", $post_html); $index++; } file_put_contents("articles_page{$page}.txt", ob_get_clean()); }
最后,再编写一个shell脚本,用于调起PHP生成所有文件内容并按照HTML模板完成写入。一个动态生成WordPress站点兼容旧设备静态页面的工具便完成了。脚本代码如下: #!/bin/bash …… # generate all post page php generate.php # render all page for i in {0..9}; do if [ -f "articles_page${i}.txt" ]; then sed -i 's/…/.../g' articles_page${i}.txt page=index.html [ $i -gt 0 ] && page="index$((i+1)).html" PAGINATION="" [ -f "articles_page$((i+1)).txt" ] && PAGINATION="<a href=\"index$((i+2)).html\"></a>" [ $i -gt 0 ] && PAGINATION="<a href=\"index$((i)).html\"></a> | $PAGINATION" sed "/<!-- Begin Articles -->/,/<!-- End Articles -->/{ /<!-- Begin Articles -->/r articles_page${i}.txt /<!-- Begin Articles -->/,/<!-- End Articles -->/d };/<!-- Begin Pagination -->/,/<!-- End Pagination -->/c\ $PAGINATION" template.html > legacy/$page fi done echo "Build OK!"
当然,为了不受HTTPS的影响,还有必要调整一下Apache的相关配置。我为这个兼容旧设备的子站点分配了一个独立的二级域名,在Apache处直接配置一个新站点,不开启HTTPS即可。
最后效果如下:
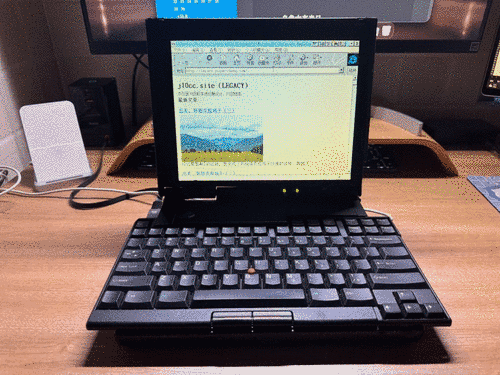 IE3的真实效果
 两种不同的移动设备浏览效果
在ThinkPad 701c的IE3上,站点完全正常浏览。当然,受限于当时显示设备的色彩还原程度,图片略微存在一些噪点。而在HP 112和Sharp Zaurus 7500c这两个世纪初的移动设备上,站点依然可以很好的适配。同时由于显示设备的进步,图片显示也更加清晰。
http://legacy.yiqun-cheng.com,旧式门户欢迎访问。
相关代码已开源:https://github.com/j-10cc/WPSiteForLegacyBrowser.git。后续也将继续迭代相关内容,比如增添多媒体文件(视频、音频)等兼容性处理。欢迎关注。 返回首页 |